ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
Python PDFライブラリ


急速に変化する技術分野において、スケーラブルで効果的なコンピューティングソリューションの必要性はこれまでになく増しています。 分散コンピューティングは、大量の分散データ処理、同時ユーザーリクエスト、および計算負荷の高いタスクを含む作業にますます必要とされています。 開発者がDistributed Pythonを完全に活用できるようにするために、本記事ではそのアプリケーション、原則、およびツールについて検討します。
ウェブ開発の分野では、動的にPDFドキュメントを生成および修正することが一般的な要件です。 プログラムを使ってPDFを作成する機能は、その場で請求書、レポート、証明書を生成する際に便利です。
Pythonの広範なエコロジーと多用途性により、多数のPDFライブラリに対応することが可能です。 IronPDFは、PDFの作成プロセスを効率化し、タスクの並行処理と分散コンピューティングを可能にすることで、開発者がインフラストラクチャを最大限に活用できる強力なソリューションです。
基本的に、分散Pythonとは、計算作業をより小さな部分に分割し、それらを複数のノード(または処理ユニット)に分配するプロセスです。 これらのノードは、ネットワークに接続された個々のマシン、システム内の個々のCPUコア、リモートオブジェクト、リモート関数、リモートまたは関数呼び出しの実行、さらには単一プロセス内の個々のスレッドである可能性があります。 目的は、ワークロードを並列化することにより、パフォーマンス、スケーラビリティ、および障害耐性を向上させることです。
Pythonは、その使いやすさ、適応性、そして豊富なライブラリエコシステムのため、分散コンピューティングワークロードに最適な選択です。 Pythonは、Celery、Dask、Apache Sparkのような強力なフレームワークから、multiprocessingやthreadingのような組み込みモジュールまで、あらゆる規模とユースケースに対応するための豊富な分散コンピューティングツールを提供しています。
詳細に入る前に、Distributed Python が基づいている基本的なアイデアと前提を見ていきましょう。
並列処理は複数のタスクを同時に実行することを意味しますが、並行処理は必ずしも同時にではなく、同時に進行しているかもしれない多くのタスクを処理することに関係しています。 タスクやシステムの設計に応じて、分散Pythonは並列性と同時性の両方をカバーしています。
並列および分散コンピューティングの重要な要素は、複数のノードや処理ユニット間で作業を分配することです。 効果的な作業分配は、全体的なパフォーマンス、効率、およびリソース使用の最適化において重要です。これは、計算プログラムの関数実行が複数のコアにわたって並列化される場合や、データ処理パイプラインがより小さなステージに分割される場合でも同様です。
分散システムにおいて、ノード間の効果的なコミュニケーションと調整は、リモート関数の実行、複雑なワークフロー、データ交換、および計算同期のオーケストレーションを促進するために不可欠です。
分散Pythonプログラムは、リモートと実際の機能実行間のスムーズな調整と通信を可能にするメッセージキュー、分散データ構造、リモートプロシージャコール(RPC)などの技術の恩恵を受けます。
システムが異なるマシンにノードや処理ユニットを追加することで増加する作業負荷に対応できる能力を、スケーラビリティと呼びます。 対照的に、フォールトトレラントとは、機械の故障、ネットワークの分割、ノードのクラッシュなどの不具合に耐え、依然として信頼性高く機能するシステムの設計を指します。
分散型アプリケーションの安定性と回復力を複数のマシンにわたって保証するために、分散型Pythonフレームワークはしばしばフォールトトレランスと自動スケーリング機能を備えています。
データ処理と分析: 大規模データセットは、Apache Spark や Dask のような分散Pythonフレームワークを使用して並行処理されることがあります。これにより、分散Pythonアプリケーションがバッチ処理、リアルタイムストリーム処理、機械学習のような活動を大規模に実行することが可能になります。
マイクロサービスによるウェブ開発: FlaskやDjangoのようなPythonウェブフレームワークとCeleryのような分散タスクキューを組み合わせることで、スケーラブルなウェブアプリケーションやマイクロサービスアーキテクチャを作成できます。 Webアプリケーションは、分散キャッシュ、非同期リクエスト処理、およびバックグラウンドジョブ処理といった機能を簡単に組み込むことができます。
科学計算とシミュレーション: 高性能計算 (HPC) および複数のマシンによるクラスタ上での並列シミュレーションは、Pythonの強力な科学ライブラリと分散コンピューティングフレームワークのエコシステムにより可能です。 アプリケーションには、金融リスク分析、気候モデリング、機械学習アプリケーション、物理学および計算生物学のシミュレーションが含まれます。
エッジコンピューティングとモノのインターネット (IoT): IoTデバイスとエッジコンピューティング設計が普及する中で、分散Pythonは、センサーデータの処理、エッジコンピューティングプロセスの調整、分散アプリケーションの共同構築、エッジでの現代的なアプリケーションのための分散機械学習モデルの実践においてますます重要になります。
並列コンピューティングフレームワークDaskを機械学習の作業に拡張する強力なライブラリDask-ML。 タスクを複数のコアまたはクラスターマシンのプロセッサに分割することで、Pythonデベロッパーは大規模なデータセットに対して効率的に分散マシンラーニングモデルを訓練および適用することが可能になります。
import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")python強力な分散計算フレームワークRayを使用すると、クラスターの多数のコアやコンピューター上でPython関数やタスクを同時に実行できます。 @ray.remoteデコレーターを利用することにより、Rayは関数をリモートとして指定することを可能にします。 その後、これらのリモートタスクまたは操作はクラスターのRayワーカーで非同期に実行できます。
import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()python私たちは、よく知られているIronPDF for .NETパッケージを使用して、.NETプログラム内でPDFドキュメントの作成、変更、レンダリングを行うことができます。 PDFの操作はさまざまな方法で行えます。HTMLコンテンツ、写真、または生データから新しいPDFドキュメントを作成することから、既存のPDFからテキストや画像を抽出すること、HTMLページをPDFに変換すること、既存のPDFにテキスト、画像、および形状を追加することなどが含まれます。
IronPDFのシンプルさと使いやすさは、その主な利点の2つです。 開発者は、使いやすいAPIと充実したドキュメントのおかげで、.NETアプリケーション内で簡単にPDFを作成することができます。 IronPDFのスピードと効率性は、デベロッパーが高品質のPDFドキュメントを迅速に作成しやすくするもう一つの特徴です。
鉄PDFのいくつかの利点
クラスター内の多数のコアまたはコンピュータにタスクを分散することは、Dask や Ray などの分散Pythonフレームワークによって可能になります。 これにより、クラスター全体で並列的にPDF生成のような複雑なタスクを実行し、それらの中で複数のコアを活用することが可能になります。これにより、大量のPDFを生成するために必要な時間が大幅に削減されます。
まず、pipを使用してIronPDFとrayライブラリをインストールします。
pip install ironpdf
pip install celerypip install ironpdf
pip install celeryここに、IronPDF と Python を使用した分散PDF生成の2つのメソッドを示す概念的なPythonコードがあります。
中央ワーカー (worker.py):
from ironpdf import *
from celery import *
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])pythonクライアントスクリプト (client.py):
from celery import Celery
app = Celery('pdf_tasks', broker='amqp://localhost')
def main():
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.result) # Wait for task completion and print result
if __name__ == '__main__':
main()pythonCeleryは私たちが利用しているタスクキューシステムです。 ジョブは、HTMLコンテンツを含むデータ辞書と共に中央の作業者(worker.py)に送信されます。 このPython関数はIronPDFを使用してPDFを作成し、特別なファイル名で保存します。
サンプルデータを含むタスクは、クライアントスクリプト(client.py)によってキューに送信されます。 このスクリプトは、他のコンピューターからのタスクを送信するように変更できます。

以下は、上記のコードから生成されたPDFです。
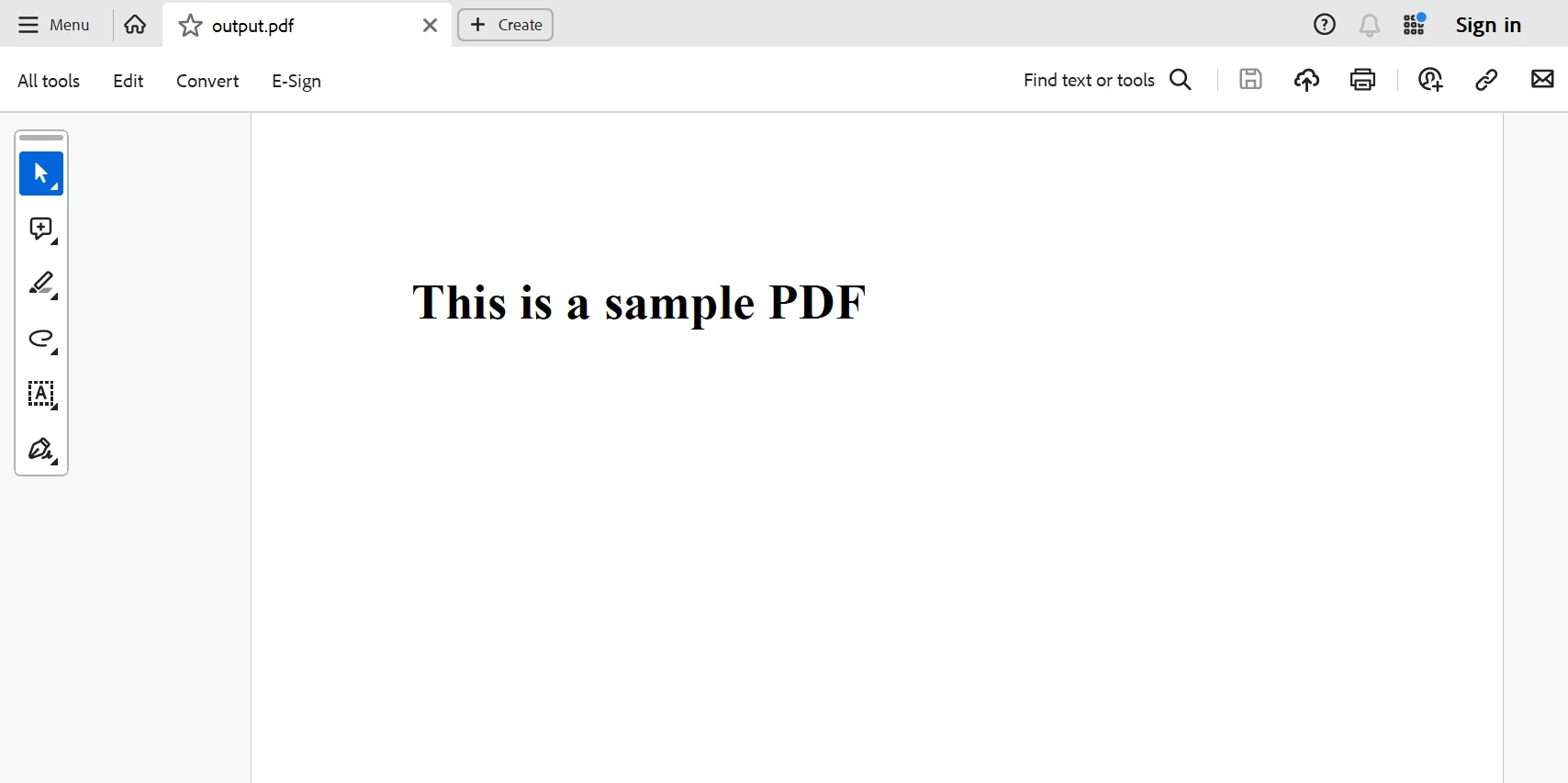
IronPDFのユーザーで、大規模なPDF作成活動を行う場合、分散型PythonやRayやDaskのようなライブラリを活用することで、膨大な潜在能力を引き出すことができます。 単一のマシン上でコードを実行する場合と比べると、同じコードの作業負荷を複数のコアに分散し、複数のマシンで使用することで、速度改善が著しく向上する可能性があります。
IronPDF は、大規模データセットを効果的に管理するための信頼性の高いソリューションに、分散型のPythonプログラミング言語を活用して、単一システムでPDFを作成する強力なツールから強化される可能性があります。 あなたの次の大規模なPDF作成プロジェクトでIronPDFを十分に活用するために、提供されているPythonライブラリを調査し、これらのメソッドを試してみてください!
IronPDF はパッケージとして購入すると合理的な価格で、永久ライセンスが付属しています。 このパッケージは素晴らしい価値があり、多くのシステムでは$749で購入できます。 ライセンス保有者には、24時間365日のオンラインエンジニアリングサポートを提供しています。 詳細な料金情報については、ウェブサイトをご覧ください。Iron Software が提供する製品の詳細については、こちらのページをご覧ください。
`pip install ironpdf`

pip install 製品名-製品バージョン-py37-none-win_amd64.whlクレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。

無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス




![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。

30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために