
ライブ環境でテストする
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
Java PDF ライブラリ


Javaプログラミングの分野において、効率的な文字列操作は基礎的なスキルです。 文字列を解析、分割、および操作する能力は、データ処理からテキスト解析までのさまざまなタスクにおいて不可欠です。 Javaで文字列を分割する基本的な方法の一つはsplit()メソッドです。
この記事では、Java Split Pipeメソッドの複雑さに入り込み、特にパイプを使用したその使用法に焦点を当てます。 ) セパレーター。 また、Javaの区切り文字であるパイプを使用して文字列を分割し、IronPDF for Javaを用いてPDFファイルを作成します。
split() メソッドは、Java の String クラスによって提供される便利なツールで、指定されたデリミタに基づいて文字列をサブストリングの配列に分割することを可能にします。 そのシグネチャは次の通りです:
public String[] split(String regex)public String[] split(String regex)ここで、regex は、文字列を分割するために使用されるデリミタを定義する正規表現です。 正規表現は、テキストのマッチングと操作のためのパターンを指定する強力な方法を提供します。
セパレーター
パイプ( ) 文字は、正規表現を含む様々なコンテキストで代替の区切り文字として機能します。 Javaでは、パイプ記号は正規表現におけるメタキャラクターとして扱われ、論理OR演算を示します。 split() メソッド内で使用すると、パイプ文字はデリミタとして機能し、文字列が出現する場所で分割します。
基本的な例を使って、split() メソッドでパイプ区切り文字を使用する方法を説明しましょう。
public class SplitExample {
public static void main(String[] args) {
String text = "apple
banana
orange
grape";
String[] fruits = text.split("\\
");
for (String fruit : fruits) {
System.out.println(fruit);
}
}
}public class SplitExample {
public static void main(String[] args) {
String text = "apple
banana
orange
grape";
String[] fruits = text.split("\\
");
for (String fruit : fruits) {
System.out.println(fruit);
}
}
}この例では、文字列"apple バナナ オレンジ grapeは、パイプ文字を使って文字列に分割されます( ) をデリミタとして使用します。 二重バックスラッシュ (\) は、パイプ文字をエスケープするために使用されます。これは正規表現におけるメタ文字だからです。

区切り文字としてパイプ記号などの特殊文字を使用する場合、予期しない動作を避けるために適切に処理することが重要です。 正規表現ではパイプ記号が特定の意味を持っているため、リテラル文字として扱うにはエスケープする必要があります。 これは、前の例に示されているように、バックスラッシュ(\)で前置することで達成されます。
split() メソッドの強みの一つは、複数の区切り文字に基づいて文字列を分割できることです。 これは、区切り文字の間で論理ORを表す正規表現を構築することによって達成されます。 例えば:
String text = "apple,banana;orange
grape";
String[] fruits = text.split("[,;\\
]");String text = "apple,banana;orange
grape";
String[] fruits = text.split("[,;\\
]");この例では、文字列"apple,banana;orange grapeは、カンマ (,)、セミコロン (;)、およびパイプ文字 () に一致する正規表現を使用して分割されます )。
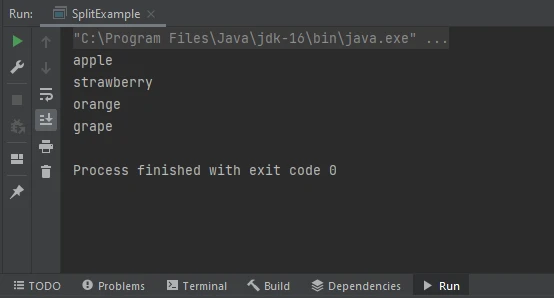
デフォルトでは、split() メソッドは連続するデリミタによって生じた空の文字列を削除します。 しかし、空の文字列を保持することが望ましいシナリオがあります。 これを達成するために、split()メソッドの第2引数として負の制限を指定できます。 例えば:
String text = "apple
banana
orange";
String[] fruits = text.split("\\
", -1);String text = "apple
banana
orange";
String[] fruits = text.split("\\
", -1);この例では、パイプ文字( 区切り文字としてが使用され、空の文字列を保持するために負の限界が指定されています。 その結果、配列fruitsは区切り文字のすべての出現、連続するものを含む要素を持ちます。

IronPDF for Java は、開発者がJavaアプリケーション内でPDFドキュメントを作成、操作、レンダリングできる強力なライブラリです。 それはPDF生成の複雑さを抽象化する直感的なAPIを提供し、開発者が低レベルのPDF操作タスクに取り組むのではなく、アプリケーションの構築に専念できるようにします。
ソフトウェア開発の分野では、プログラムを通じてPDFドキュメントを生成することは一般的な要件です。 レポート、請求書、または証明書の生成であっても、動的にPDFを作成する信頼できるツールを持つことは重要です。 Java開発者にとってPDF生成を簡素化するツールの一つがIronPDFです。
IronPDFを設定するためには、信頼できるJavaコンパイラが必要です。 このチュートリアルでは、IntelliJ IDEAを使用します。
IntelliJ IDEAを起動し、新しいMavenプロジェクトを開始します。
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>com.ironsoftware</artifactId>
<version>2024.3.1</version>
</dependency> <dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>com.ironsoftware</artifactId>
<version>2024.3.1</version>
</dependency>import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Apply your license key
License.setLicenseKey("YOUR-LICENSE-KEY");
String data = "Item1
Item2
Item3
Item4
Item5";
// Split data into a list
String[] items = data.split("\\
");
// Create HTML list
StringBuilder htmlList = new StringBuilder("<ul>\n");
for (String item : items) {
htmlList.append(" <li>").append(item).append("</li>\n");
}
htmlList.append("</ul>");
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf(htmlList.toString());
// Save the PdfDocument to a file
myPdf.saveAs(Paths.get("htmlCode.pdf"));import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Apply your license key
License.setLicenseKey("YOUR-LICENSE-KEY");
String data = "Item1
Item2
Item3
Item4
Item5";
// Split data into a list
String[] items = data.split("\\
");
// Create HTML list
StringBuilder htmlList = new StringBuilder("<ul>\n");
for (String item : items) {
htmlList.append(" <li>").append(item).append("</li>\n");
}
htmlList.append("</ul>");
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf(htmlList.toString());
// Save the PdfDocument to a file
myPdf.saveAs(Paths.get("htmlCode.pdf"));このコードスニペットは、HTML形式の文字列からPDFドキュメントを生成する方法を示しています。 まず、PDF生成およびファイル操作に必要なライブラリをインポートします。 次に、PDF操作に使用されるライブラリであるIronPDFのライセンスキーを設定します。
文字列データはパイプ区切りの値で定義されています。 その文字列は、パイプ文字を区切り文字として使用し、items という名前の文字列配列に分割されます。
次に、HTMLリスト(htmlList)は、items 配列から各アイテムを無序リスト()内のリストアイテム()タグに追加することで構築されます。
PdfDocument.renderHtmlAsPdf() メソッドは、このHTML文字列をPDFドキュメントに変換し、saveAs() メソッドを使用して "htmlCode.pdf" として保存します。
要約すると、このコードはデータの文字列をHTMLリストとしてフォーマットし、そのHTMLをIronPDFを使用してPDFに変換し、結果のPDFを「htmlCode.pdf」として保存します。

Javaの文字列操作とPDF生成機能の包括的な概要において、特にパイプと一緒に使用されるsplit()メソッドの機能性を探りました。 ) デリミター。 split() メソッドは、指定されたデリミタに基づいて文字列を部分文字列に分割するための柔軟な方法を提供し、特殊文字や複数のデリミタの処理も可能です。 IronPDF は、Java で動的に PDF ドキュメントを生成するための強力なツールとして登場し、低レベルのPDF操作を抽象化することでプロセスを簡素化しました。
提供された例は、Javaの文字列分割機能をIronPDFと共に活用し、HTML形式の文字列をPDFドキュメントに変換する方法を示しています。これは、Javaにおける文字列操作とPDF生成のシームレスな統合を紹介しています。
ソフトウェア開発ではレポートや請求書などのPDF生成が頻繁に求められるため、これらの技術を習得することは、開発者がそのようなタスクを効率的に処理するために不可欠なスキルを身に付けることになります。
IronPDFの機能について詳しく知りたい場合は、IronPDF ドキュメントページを訪れて、IronPDFがどのようにあなたのプロジェクトを支援できるかをご覧ください。 IronPDFライセンス情報 は$749 USDから始まります。
Darrius Serrantは、マイアミ大学でコンピュータサイエンスの学士号を取得しており、Iron SoftwareでフルスタックWebOpsマーケティングエンジニアとして働いています。若い頃からコーディングに魅了され、コンピューティングを神秘的でありながらアクセスしやすいものと見なし、それが創造性と問題解決のための完璧な媒体であると感じました。
Iron Softwareでは、新しいものを作り出し、複雑な概念を簡単にすることでより理解しやすくすることを楽しんでいます。彼は常駐の開発者の一人として、学生に教えることを志願し、自分の専門知識を次世代と共有しています。
Darriusにとって、彼の仕事は評価され、実際に影響があることで充実しています。

<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2025.5.6</version>
</dependency>
クレジットカードは不要です
試用キーはメールに送信されるはずです。![]() 試用版申し込みフォームが
試用版申し込みフォームが
正常に送信されました。
もし届かない場合は、
support@ironsoftware.comにお問い合わせください。

無料で始めましょう
クレジットカードは不要です
透かしなしで本番環境でテストしてください。
必要な場所で動作します。
30日間、完全に機能する製品をご利用いただけます。
数分で稼働させることができます。
製品トライアル期間中にサポートエンジニアリングチームへの完全アクセス




![]() クレジットカードやアカウント作成は不要です。
クレジットカードやアカウント作成は不要です。
試用キーはメールにあるはずです。
もしない場合は、
support@ironsoftware.comまでご連絡ください。

30分の個別デモを予約する。
契約なし、カード情報不要、義務なし。


10 .NET API製品オフィスドキュメントのために