Test dans un environnement réel
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
La bibliothèque PDF de Python


Python est un langage puissant pour l'analyse de données et l'apprentissage automatique, mais la manipulation de grands ensembles de données peut constituer un défi pour l'analyse de données. C'est là qu'Dask entre en jeu. Dask est une bibliothèque open-source qui offre une parallélisation avancée pour l'analytique, permettant un calcul efficace sur de grands ensembles de données dépassant la capacité mémoire d'une seule machine. Dans cet article, nous examinerons l'utilisation de base de la bibliothèque Dask et une autre bibliothèque de génération de PDF très intéressante appelée IronPDF de Iron Software pour générer des documents PDF.
Dask est conçu pour faire évoluer votre code Python d'un seul ordinateur portable à un grand cluster. Il s'intègre de manière transparente aux bibliothèques Python populaires telles que NumPy, pandas et scikit-learn, pour permettre une exécution parallèle sans modification significative du code.
Calcul parallèle : Dask vous permet d'exécuter plusieurs tâches simultanément, accélérant ainsi considérablement les calculs.
Scalabilité : Il peut gérer des ensembles de données plus grands que la mémoire en les découpant en plus petits morceaux et en les traitant en parallèle.
Compatibilité : Fonctionne bien avec les bibliothèques Python existantes, ce qui facilite l'intégration dans votre flux de travail actuel.
Vous pouvez installer Dask à l'aide de pip :
pip install dask[complete]pip install dask[complete]Voici un exemple simple pour démontrer comment Dask peut paralléliser les calculs :
import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
print('Gneerated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Gneerated Mean')
print(result)pyDans cet exemple, Dask crée un grand tableau et le divise en morceaux plus petits. La méthode compute() déclenche le calcul parallèle et retourne le résultat. Le graphe des tâches est utilisé en interne pour réaliser des calculs parallèles dans Python Dask.

Les DataFrames de Dask sont similaires aux DataFrames de pandas mais sont conçues pour gérer des ensembles de données plus volumineux que la mémoire. En voici un exemple :
import dask
df = dask.datasets.timeseries()
print('\n\nGenerated DataFrame')
print(df.head(10))
print('\n\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))pyLe code montre la capacité de Dask à traiter des données chronologiques, à générer des ensembles de données synthétiques et à calculer efficacement des agrégations telles que des moyennes horaires, en tirant parti de ses capacités de traitement parallèle. Plusieurs processus Python, un planificateur distribué et des ressources informatiques à cœurs multiples sont utilisés pour réaliser le calcul parallèle dans les DataFrames de Python Dask.
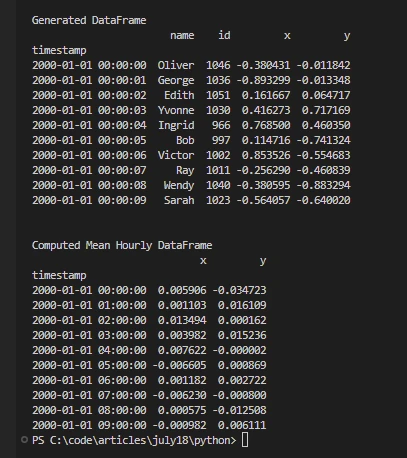
Commencez petit : Commencez avec de petits ensembles de données pour comprendre comment Dask fonctionne avant de monter en échelle.
Utilisez le Tableau de bord : Dask fournit un tableau de bord pour surveiller la progression et la performance de vos calculs.

IronPDF est une bibliothèque Python robuste conçue pour créer, modifier et signer des documents PDF en utilisant HTML, CSS, images et JavaScript. Il met l'accent sur l'efficacité des performances avec une utilisation minimale de la mémoire. Les principales caractéristiques sont les suivantes :
pip install ironpdf
pip install daskpip install ironpdf
pip install daskAssurez-vous que Visual Studio Code est installé
La version 3 de Python est installée
Pour commencer, créons un fichier Python pour ajouter nos scripts
Ouvrez Visual Studio Code et créez un fichier, daskDemo.py.
Installer les bibliothèques nécessaires :
pip install dask
pip install ironpdfpip install dask
pip install ironpdfAjoutez ensuite le code python ci-dessous pour démontrer l'utilisation d'IronPDF for Python et des paquets python Dask
import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
df = dask.datasets.timeseries()
print('\n\nGenerated DataFrame')
print(df.head(10))
print('\n\nComputed Mean Hourly DataFrame')
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print(dfmean)
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using Python
content = "<h1>Awesome Iron PDF with Dask</h1>"
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = df.head(10).iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.head(10).iloc[i]
content += f"<p>{str(row[0])}</p>"
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or Stream
pdf.SaveAs("DemoIronPDF-Dask.pdf")pyCet extrait de code intègre Dask pour le traitement des données et IronPDF pour la génération de PDF. Il démontre :
Intégration Dask : Utilise `dask.datasets.timeseries()` pour générer un DataFrame de série temporelle synthétique (`df`). Affiche les 10 premières lignes (`df.head(10)`) et calcule la moyenne horaire du DataFrame (`dfmean`) basée sur les colonnes "x" et "y".
Utilisation d'IronPDF : Définit la clé de licence IronPDF en utilisant `License.LicenseKey`. Crée une chaîne HTML (content) contenant des en-têtes et des données à partir des DataFrames générés et calculés.
Rend ce contenu HTML en PDF (`pdf`) en utilisant `ChromePdfRenderer()`.
Enregistre le PDF sous le nom "DemoIronPDF-Dask.pdf".
Ce code combine les capacités de Dask pour la manipulation de données à grande échelle et la fonctionnalité d'IronPDF pour la conversion de contenu HTML en document PDF.


Clé de licence IronPDF pour permettre aux utilisateurs de tester ses fonctionnalités étendues avant l'achat.
Placez la clé de licence au début du script avant d'utiliser le package IronPDF :
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"pyDask est un outil polyvalent qui peut améliorer considérablement vos capacités de traitement de données en Python. En permettant le calcul parallèle et distribué, il vous permet de travailler efficacement avec de grands ensembles de données et de vous intégrer de manière transparente à votre écosystème Python existant. IronPDF est une bibliothèque Python puissante pour créer et manipuler des documents PDF en utilisant HTML, CSS, des images et JavaScript. Il offre des fonctionnalités telles que la conversion de HTML en PDF, l'édition de PDF, la signature numérique et la prise en charge multiplateforme, ce qui le rend adapté à diverses tâches de génération et de gestion de documents dans les applications Python.
Avec ces deux bibliothèques, les scientifiques des données peuvent effectuer des analyses de données avancées et des opérations de science des données. Stockez ensuite les résultats de sortie au format PDF standard à l'aide d'IronPDF.
pip install ironpdf

pip install nom du produit-produit-version-py37-none-win_amd64.whiAucune carte de crédit n'est requise
Votre clé d'essai devrait se trouver dans l'email.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Aucune carte de crédit n'est requise

Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit




![]() Aucune carte de crédit ou création de compte n'est nécessaire
Aucune carte de crédit ou création de compte n'est nécessaire
Votre clé d'essai devrait être dans l'e-mail.
Si ce n'est pas le cas, veuillez contacter
support@ironsoftware.com
Commencez GRATUITEMENT
Aucune carte de crédit n'est requise
Testez en production sans filigranes.
Fonctionne là où vous en avez besoin.
Obtenez 30 jours de produit entièrement fonctionnel.
Faites-le fonctionner en quelques minutes.
Accès complet à notre équipe d'ingénieurs pendant la période d'essai du produit
Licences à partir de 749 $. Vous avez une question ? Contactez-nous.

Réservez une démonstration personnelle de 30 minutes.
Pas de contrat, pas de détails de carte, pas d'engagements.


10 produits .NET API pour vos documents de bureau