Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
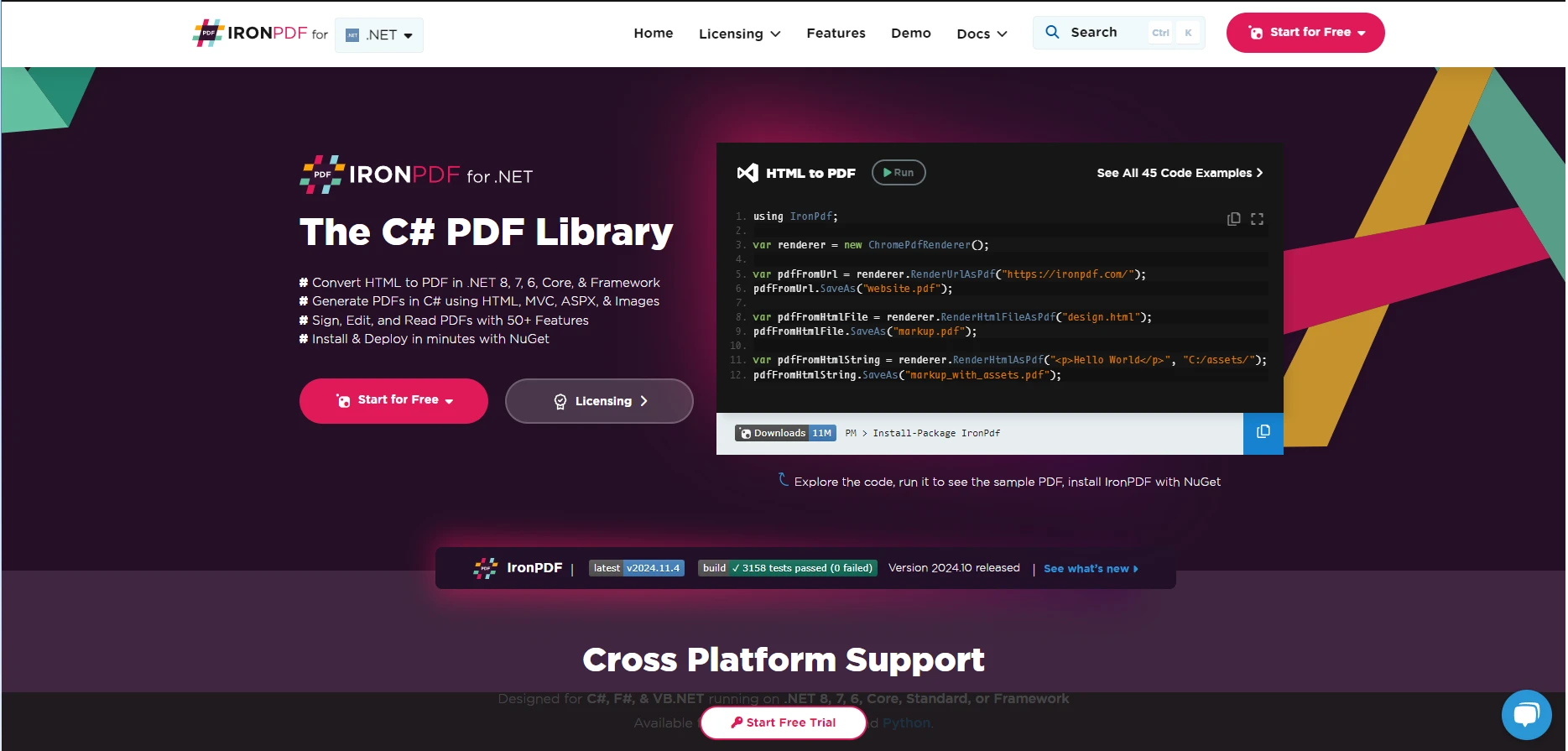
The C# PDF Library
using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");Install-Package IronPdf


Finding text within a PDF can be a challenging task, especially when working with static files that aren't easily editable or searchable. Whether you're automating document workflows, building search functionality, needing to highlight text matching your search criteria, or extracting data, text extraction is a critical feature for developers.
IronPDF, a powerful .NET library, simplifies this process, enabling developers to efficiently search for and extract text from PDFs. In this article, we'll explore how to use IronPDF to find text in a PDF using C#, complete with code examples and practical applications.
"Find text" refers to the process of searching for specific text or patterns within a document, file, or other data structures. In the context of PDF files, it involves identifying and locating instances of specific words, phrases, or patterns within the text content of a PDF document. This functionality is essential for numerous applications across industries, especially when dealing with unstructured or semi-structured data stored in PDF format.
PDF files are designed to present content in a consistent, device-independent format. However, the way text is stored in PDFs can vary widely. Text might be stored as:
This variability means that effective text search in PDFs often requires specialized libraries, like IronPDF, that can handle diverse content types seamlessly.
The ability to find text in PDFs has a wide range of applications, including:
Automating Workflows: Automating tasks like processing invoices, contracts, or reports by identifying key terms or values in PDF documents.
Data Extraction: Extracting information for use in other systems or for analysis.
Content Verification: Ensuring that required terms or phrases are present in documents, such as compliance statements or legal clauses.
Finding text in PDFs isn't always straightforward due to the following challenges:
IronPDF is designed to make PDF manipulation as seamless as possible for developers working in the .NET ecosystem. It offers a suite of features tailored to streamline text extraction and manipulation processes.
Ease of Use:
IronPDF features an intuitive API, allowing developers to get started quickly without a steep learning curve. Whether you're performing basic text extraction or HTML to PDF conversion, or advanced operations, its methods are straightforward to use.
High Accuracy:
Unlike some PDF libraries that struggle with PDFs containing complex layouts or embedded fonts, IronPDF reliably extracts text with precision.
Cross-Platform Support:
IronPDF is compatible with both .NET Framework and .NET Core, ensuring developers can use it in modern web apps, desktop applications, and even legacy systems.
Support for Advanced Queries:
The library supports advanced search techniques like regular expressions and targeted extraction, making it suitable for complex use cases like data mining or document indexing.
IronPDF is available via NuGet, making it easy to add to your .NET projects. Here's how to get started.
To install IronPDF, use the NuGet Package Manager in Visual Studio or run the following command in the Package Manager Console:
Install-Package IronPdfInstall-Package IronPdfThis will download and install the library along with its dependencies.
Once the library is installed, you need to include it in your project by referencing the IronPDF namespace. Add the following line at the top of your code file:
using IronPdf;using IronPdf;Imports IronPdfIronPDF simplifies the process of finding text within a PDF document. Below is a step-by-step demonstration of how to achieve this.
The first step is to load the PDF file you want to work with. This is done using the PdfDocument class, as seen in the following code:
using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("example.pdf")The PdfDocument class represents the PDF file in memory, enabling you to perform various operations like extracting text or modifying content. Once the PDF has been loaded, we can search text from the entire PDF document or a specific PDF page within the file.
After loading the PDF, use the ExtractAllText() method to extract the text content of the entire document. You can then search for specific terms using standard string manipulation techniques:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim path As String = "example.pdf"
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile(path)
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for a specific term
Dim searchTerm As String = "Invoice"
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
Console.WriteLine(If(isFound, $"The term '{searchTerm}' was found in the PDF!", $"The term '{searchTerm}' was not found."))
End Sub
End ClassInput PDF

Console Output

This example demonstrates a simple case where you check if a term exists in the PDF. The StringComparison.OrdinalIgnoreCase ensures that the searched text is case-insensitive.
IronPDF offers several advanced features that extend its text search capabilities.
Regular expressions are a powerful tool for finding patterns within text. For example, you might want to locate all email addresses in a PDF:
using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}Imports System.Text.RegularExpressions ' Required namespace for using regex
' Extract all text
Private pdfText As String = pdf.ExtractAllText()
' Use a regex to find patterns (e.g., email addresses)
Private regex As New Regex("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")
Private matches As MatchCollection = regex.Matches(pdfText)
For Each match As Match In matches
Console.WriteLine($"Found match: {match.Value}")
Next matchInput PDF

Console Output

This example uses a regex pattern to identify and print all email addresses found in the document.
Sometimes, you may only need to search within a specific page of a PDF. IronPDF allows you to target individual pages using the PdfDocument.Pages property:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("urlPdf.pdf")
' Extract text from the first page
Dim pageText = pdf.Pages(0).Text.ToString()
If pageText.Contains("IronPDF") Then
Console.WriteLine("Found the term 'IronPDF' on the first page!")
End If
End Sub
End ClassInput PDF

Console Output

This approach is useful for optimizing performance when working with large PDFs.
Legal professionals can use IronPDF to automate the search for key terms or clauses within lengthy contracts. For example, quickly locate "Termination Clause" or "Confidentiality" in documents.
In finance or accounting workflows, IronPDF can help locate invoice numbers, dates, or total amounts in bulk PDF files, streamlining operations and reducing manual effort.
IronPDF can be integrated into data pipelines to extract and analyze information from reports or logs stored in PDF format. This is particularly useful for industries dealing with large volumes of unstructured data.
IronPDF is more than just a library for working with PDFs; it’s a complete toolkit that empowers .NET developers to handle complex PDF operations with ease. From extracting text and finding specific terms to performing advanced pattern matching with regular expressions, IronPDF streamlines tasks that might otherwise require significant manual effort or multiple libraries.
The ability to extract and search text in PDFs unlocks powerful use cases across industries. Legal professionals can automate the search for critical clauses in contracts, accountants can streamline invoice processing, and developers in any field can create efficient document workflows. By offering precise text extraction, compatibility with .NET Core and Framework, and advanced capabilities, IronPDF ensures that your PDF needs are met without hassle.
Don't let PDF processing slow down your development. Start using IronPDF today to simplify text extraction and boost productivity. Here's how you can get started:
Take the first step toward optimizing your document workflows with IronPDF. Unlock its full potential, enhance your development process, and deliver robust, PDF-powered solutions faster than ever.
Finding text in PDFs using C# is essential for automating workflows, building search functionality, highlighting matching text, and extracting data. It is particularly useful when dealing with static files that aren’t easily editable or searchable.
Challenges in text search in PDFs include encoding variations, fragmented text, text embedded in graphics requiring OCR, and the need for multilingual support.
IronPDF provides ease of use with its intuitive API, high accuracy in extracting text from complex layouts, cross-platform support, and advanced search techniques like regular expressions.
You can install IronPDF via NuGet by using the Package Manager in Visual Studio or the following command: Install-Package IronPdf.
Yes, IronPDF can handle text embedded in images by using OCR (Optical Character Recognition) to convert it into searchable text.
IronPDF can be used for contract analysis by legal professionals, invoice processing in finance, and data mining in any industry dealing with large volumes of unstructured data.
IronPDF ensures high accuracy by effectively handling PDFs with complex layouts or embedded fonts, reliably extracting text with precision.
IronPDF offers advanced features such as using regular expressions for pattern matching and the ability to extract text from specific pages within a PDF.
Yes, IronPDF is compatible with both .NET Framework and .NET Core, allowing developers to use it in modern web apps, desktop applications, and legacy systems.
To get started with IronPDF, you can download the free trial, explore the documentation for detailed guides and examples, and start implementing PDF functionality in your .NET applications.
Install-Package IronPdf

No credit card required
Your trial key should be in the email.![]() The trial form was submitted
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
No credit card required
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial




![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
Book a 30-minute, personal demo.
No contract, no card details, no commitments.


10 .NET API products for your office documents